前端二进制数据处理
date
Mar 9, 2020
slug
binary-data-process
status
Published
tags
二进制
summary
最近在前端项目中需要对二进制数据做一些数据处理。平时使用的很少,发现很多概念都是混淆,这里特别总结一些常见的使用
type
Post
Browser二进制数据对象ArrayBufferTypedArray什么是视图TypedArray视图实例构造函数属性/方法DataView构造函数属性方法场景AJAXFetch APICanvasWebSocketFile APIBlobObject URLBlob API构造函数Blob 属性Blob 方法常用转换字符串转BlobBlob转字符串Blob转ArrayBufferArrayBuffer转BlobTypedArray转BlobBase64浏览器处理APINode.jsBuffer全局对象字符编码Buffer 与 TypedArray参考
最近在前端项目中需要对二进制数据做一些数据处理。平时使用的很少,发现很多概念都是混淆,这里特别总结一些常见的使用
Browser二进制数据对象
ArrayBuffer
“用来表示「通用的、固定长度的」原始二进制数据缓冲区” ——MDN
ArrayBuffer 是一个字节数组,通常在其他语言中称为 “byte array”
它代表内存之中的一段二进制数据,不能直接操作,而是要通过视图(类型数组对象 或 DataView 对象)来操作。视图的操作都会响应到对应的 ArrayBuffer
- 构造函数创建
// length 单位字节
new ArrayBuffer(length)- 属性/方法
isView: 静态方法 isView,如果参数是 ArrayBuffer 的视图实例则返回 true,例如 类型数组对象 或 DataView 对象
const buffer = new ArrayBuffer(8);
ArrayBuffer.isView(buffer) // false
const v = new Int32Array(buffer);
ArrayBuffer.isView(v) // truebyteLength:数组的字节大小。访问器属性,不可更改parseInt(buffer.byteLength / 1024);//文件大小,单位KB;.slice():返回一个新的 ArrayBuffer ,它的内容是这个 ArrayBuffer 的字节副本,从begin(包括),到end(不包括)slice方法其实包含两步,第一步是先分配一段新内存,第二步是将原来那个ArrayBuffer对象拷贝过去
TypedArray
什么是视图
同一段内存,不同数据有不同的解读方式,这就叫做“视图”(view)
TypedArray视图
“一个类型化数组(TypedArray)对象描述了一个底层的二进制数据缓冲区的一个类数组视图(view)” ——MDN
共包括 9 种类型的视图,比如 Uint8Array(无符号 8 位整数)数组视图, Int16Array(16 位整数)数组视图, Float32Array(32 位浮点数)数组视图等等
数组成员都是同一个数据类型
实例
实例它们很像普通数组,都有length属性,都能用方括号运算符([])获取单个元素,所有数组的方法,在它们上面都能使用(没有concat方法)。普通数组与 TypedArray 数组的差异主要在以下方面
- TypedArray 数组的所有成员,都是同一种类型。
- TypedArray 数组的成员是连续的,不会有空位。
- TypedArray 数组成员的默认值为 0。比如,
new Array(10)返回一个普通数组,里面没有任何成员,只是 10 个空位;new Uint8Array(10)返回一个 TypedArray 数组,里面 10 个成员都是 0。
- TypedArray 数组只是一层视图,本身不储存数据,它的数据都储存在底层的
ArrayBuffer对象之中,要获取底层对象必须使用buffer属性
构造函数
第一种构造函数调用,从ArrayBuffer对象创建
TypedArray(buffer, byteOffset=0, length?)// 创建一个8字节的ArrayBuffer
const b = new ArrayBuffer(8);
// 创建一个指向b的Int32视图,开始于字节0,直到缓冲区的末尾
const v1 = new Int32Array(b);
// 创建一个指向b的Uint8视图,开始于字节2,直到缓冲区的末尾
const v2 = new Uint8Array(b, 2);
// 创建一个指向b的Int16视图,开始于字节2,长度为2
const v3 = new Int16Array(b, 2, 2);
// 这其中,只要任何一个视图对内存有所修改,就会在另外两个视图上反应出注意,byteOffset必须与所要建立的数据类型一致,否则会报错。如下👇
const buffer = new ArrayBuffer(8);
const i16 = new Int16Array(buffer, 1);
// Uncaught RangeError: start offset of Int16Array should be a multiple of 2上面代码中,新生成一个 8 个字节的ArrayBuffer对象,然后在这个对象的第一个字节,建立带符号的 16 位整数视图,结果报错。因为,Int16Array相当于会去用16位表示一个整数,带符号的 16 位整数需要两个字节,所以byteOffset参数必须能够被 2 整除。(如果想从任意字节开始解读ArrayBuffer对象,必须使用DataView视图,因为TypedArray视图只提供 9 种固定的解读格式)
第二种构造函数调用,直接分配内存
TypedArray(length)
const f64a = new Float64Array(8);
f64a[0] = 10;
f64a[1] = 20;
f64a[2] = f64a[0] + f64a[1];第三种构造函数调用,接受另外一个TypedArray实例作为参数
TypedArray(typedArray)
const typedArray = new Int8Array(new Uint8Array(4));注意,此时生成的新数组,只是复制了参数数组的值,对应的底层内存是不一样的。新数组会开辟一段新的内存储存数据,不会在原数组的内存之上建立视图。
基于同一段内存创建,可以采用下面的方式
const x = new Int8Array([1, 1]);
const y = new Int8Array(x.buffer);
x[0] // 1
y[0] // 1
x[0] = 2;
y[0] // 2第四种构造函数调用:接受一个普通数组对象
这时TypedArray视图会重新开辟内存,不会在原数组的内存上建立视图
TypedArray(arrayLikeObject)
const typedArray = new Uint8Array([1, 2, 3, 4]);
const normalArray = [...typedArray];
// or
const normalArray = Array.from(typedArray);
// or
const normalArray = Array.prototype.slice.call(typedArray);属性/方法
byteLength
TypedArray 数组占据的内存长度,单位为字节
byteOffset
TypedArray 数组从底层ArrayBuffer对象的哪个字节开始
length
表示 TypedArray 数组含有多少个成员
set()
用于复制数组(普通数组或 TypedArray 数组),也就是将一段内容完全复制到另一段内存。
const a = new Uint8Array(8);
const b = new Uint8Array(8);
b.set(a);subarray()
对于 TypedArray 数组的一部分,再建立一个新的视图
slice()
可以返回一个指定位置的新的TypedArray实例
TypedArray.of()
构造函数,都有一个静态方法of,用于将参数转为一个TypedArray实例
// 下面三种方法都会生成同样一个 TypedArray 数组
// 方法一
let tarr = new Uint8Array([1,2,3]);
// 方法二
let tarr = Uint8Array.of(1,2,3);
// 方法三
let tarr = new Uint8Array(3);
tarr[0] = 1;
tarr[1] = 2;
tarr[2] = 3;TypedArray.from()
静态方法from接受一个可遍历的数据结构(比如数组)作为参数,返回一个基于这个结构的TypedArray实例
DataView
"DataView 视图是一个可以从 二进制 ArrayBuffer 对象中读写多种数值类型的底层接口,使用它时,不用考虑不同平台的字节序问题" ——MDN
什么是字节序
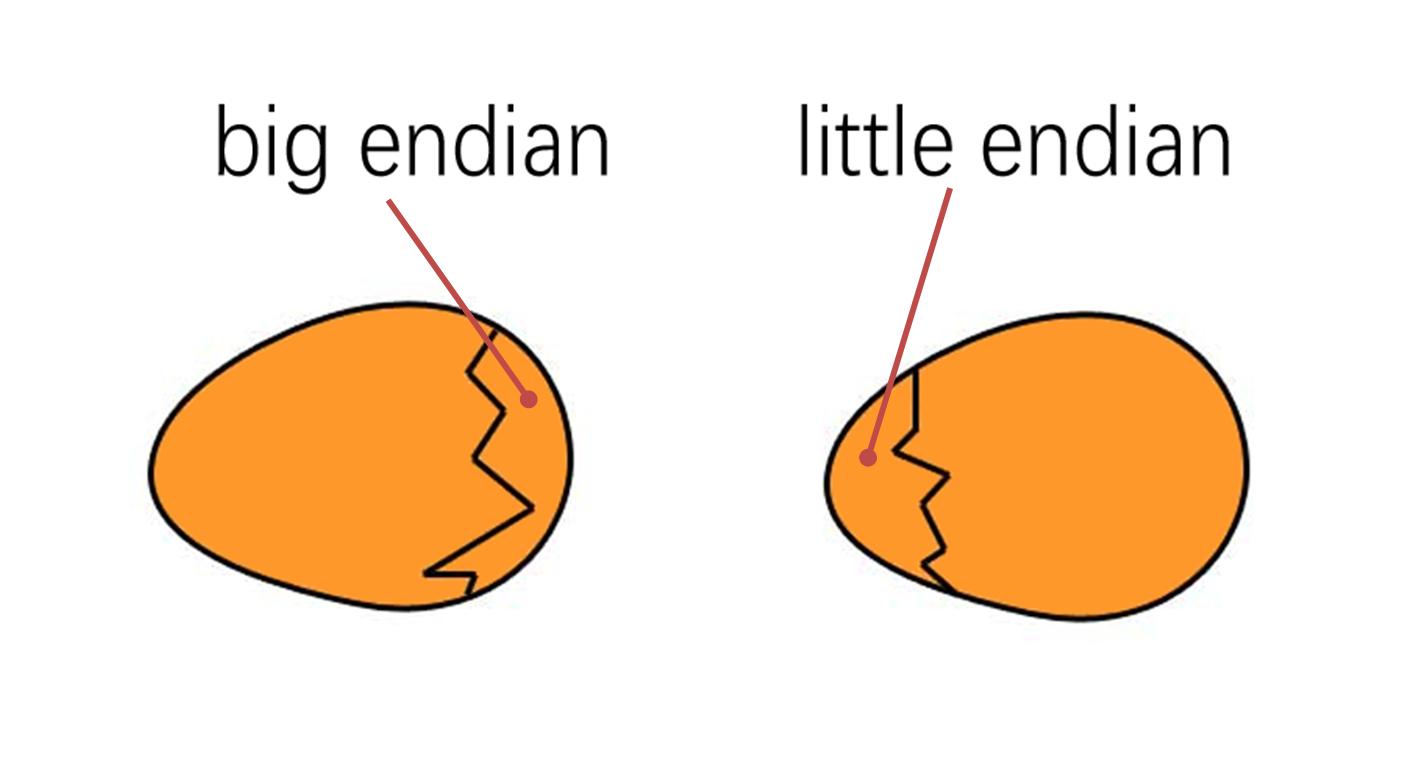
字节序指的是数值在内存中的表示方式。
什么是小端字节序,什么是大端字节序呢,简单来说就是如何按顺序存储字节到内存地址的问题
低位存储在前即小端字节序👇

高位存储在前即大端字节序👇

因此产生了计算机界的大端与小端之争,不同的CPU厂商并没有达成一致。x86 体系的计算机都采用小端字节序(little endian)
网络中的字节序
当然对于本机来说,你想怎么存就怎么存,但是网络的诞生就不一样了
TCP/IP协议出场,RFC1700规定使用“大端”字节序为网络字节序,其他不使用大端的计算机要注意了,发送数据的时候必须要将自己的主机字节序转换为网络字节序(即“大端”字节序),接收到的数据再转换为自己的主机字节序。这样就与CPU、操作系统无关了,实现了网络通信的标准化
相比TypedArray,DataView 数组成员可以是不同的数据类型
DataView视图提供更多操作选项,而且支持设定字节序。本来,在设计目的上,ArrayBuffer对象的各种TypedArray视图,是用来向网卡、声卡之类的本机设备传送数据,所以使用本机的字节序就可以了;而DataView视图的设计目的,是用来处理网络设备传来的数据,所以大端字节序或小端字节序是可以自行设定的
你可以把返回的对象想象成一个二进制字节缓存区 array buffer 的 “解释器” —— 它知道如何在读取或写入时正确地转换字节码。这意味着它能在二进制层面处理整数与浮点转化、字节顺序等其他有关的细节问题
构造函数
new DataView(ArrayBuffer buffer [, 字节起始位置 [, 长度]]);属性
含义与TypedArray实例的同名方法相同
DataView.prototype.buffer:返回对应的 ArrayBuffer 对象
DataView.prototype.byteLength:返回占据的内存字节长度
DataView.prototype.byteOffset:返回当前视图从对应的 ArrayBuffer 对象的哪个字节开始
方法
读取内存
getInt8:读取 1 个字节,返回一个 8 位整数。
getUint8:读取 1 个字节,返回一个无符号的 8 位整数。
getInt16:读取 2 个字节,返回一个 16 位整数。
getUint16:读取 2 个字节,返回一个无符号的 16 位整数。
getInt32:读取 4 个字节,返回一个 32 位整数。
getUint32:读取 4 个字节,返回一个无符号的 32 位整数。
getFloat32:读取 4 个字节,返回一个 32 位浮点数。
getFloat64:读取 8 个字节,返回一个 64 位浮点数。
如果一次读取两个或两个以上字节,就必须明确数据的存储方式,到底是小端字节序还是大端字节序。默认情况下,DataView的get方法使用大端字节序解读数据,如果需要使用小端字节序解读,必须在get方法的第二个参数指定true
写入内存
setInt8:写入 1 个字节的 8 位整数。
setUint8:写入 1 个字节的 8 位无符号整数。
setInt16:写入 2 个字节的 16 位整数。
setUint16:写入 2 个字节的 16 位无符号整数。
setInt32:写入 4 个字节的 32 位整数。
setUint32:写入 4 个字节的 32 位无符号整数。
setFloat32:写入 4 个字节的 32 位浮点数。
setFloat64:写入 8 个字节的 64 位浮点数。
这一系列set方法,接受两个参数,第一个参数是字节序号,表示从哪个字节开始写入,第二个参数为写入的数据。对于那些写入两个或两个以上字节的方法,需要指定第三个参数,false或者undefined表示使用大端字节序写入,true表示使用小端字节序写入
场景
AJAX
let xhr = new XMLHttpRequest();
xhr.open('GET', someUrl);
xhr.responseType = 'arraybuffer';
xhr.onload = function () {
let arrayBuffer = xhr.response;
// ···
};
xhr.send();Fetch API
fetch(url)
.then(function(response){
return response.arrayBuffer()
})
.then(function(arrayBuffer){
// ...
});Canvas
网页Canvas元素输出的二进制像素数据,就是 TypedArray 数组。
const canvas = document.getElementById('myCanvas');
const ctx = canvas.getContext('2d');
const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
const uint8ClampedArray = imageData.data;WebSocket
let socket = new WebSocket('ws://127.0.0.1:8081');
socket.binaryType = 'arraybuffer';
// Wait until socket is open
socket.addEventListener('open', function (event) {
// Send binary data
const typedArray = new Uint8Array(4);
socket.send(typedArray.buffer);
});
// Receive binary data
socket.addEventListener('message', function (event) {
const arrayBuffer = event.data;
// ···
});File API
const fileInput = document.getElementById('fileInput');
const file = fileInput.files[0];
const reader = new FileReader();
reader.readAsArrayBuffer(file);
reader.onload = function () {
const arrayBuffer = reader.result;
// ···
};Blob
Object URL

Object URL 是一种伪协议,也被称为 Blob URL。它允许 Blob 或 File 对象用作图像,下载二进制数据链接等的 URL 源
在浏览器中,我们使用
URL.createObjectURL 方法来创建 Blob URL,该方法接收一个 Blob 对象,并为其创建一个唯一的 URL,其形式为 blob:<origin>/<uuid>,对应的示例如下:blob:https://example.org/40a5fb5a-d56d-4a33-b4e2-0acf6a8e5f641浏览器内部为每个通过
URL.createObjectURL 生成的 URL 存储了一个 「URL → Blob」 映射。因此,此类 URL 较短,但可以访问 Blob。生成的 URL 仅在当前文档打开的状态下才有效。但如果你访问的 Blob URL 不再存在,则会从浏览器中收到 404 错误可以调用 URL.revokeObjectURL(url) 方法,从内部映射中删除引用,从而允许删除 Blob(如果没有其他引用),并释放内存
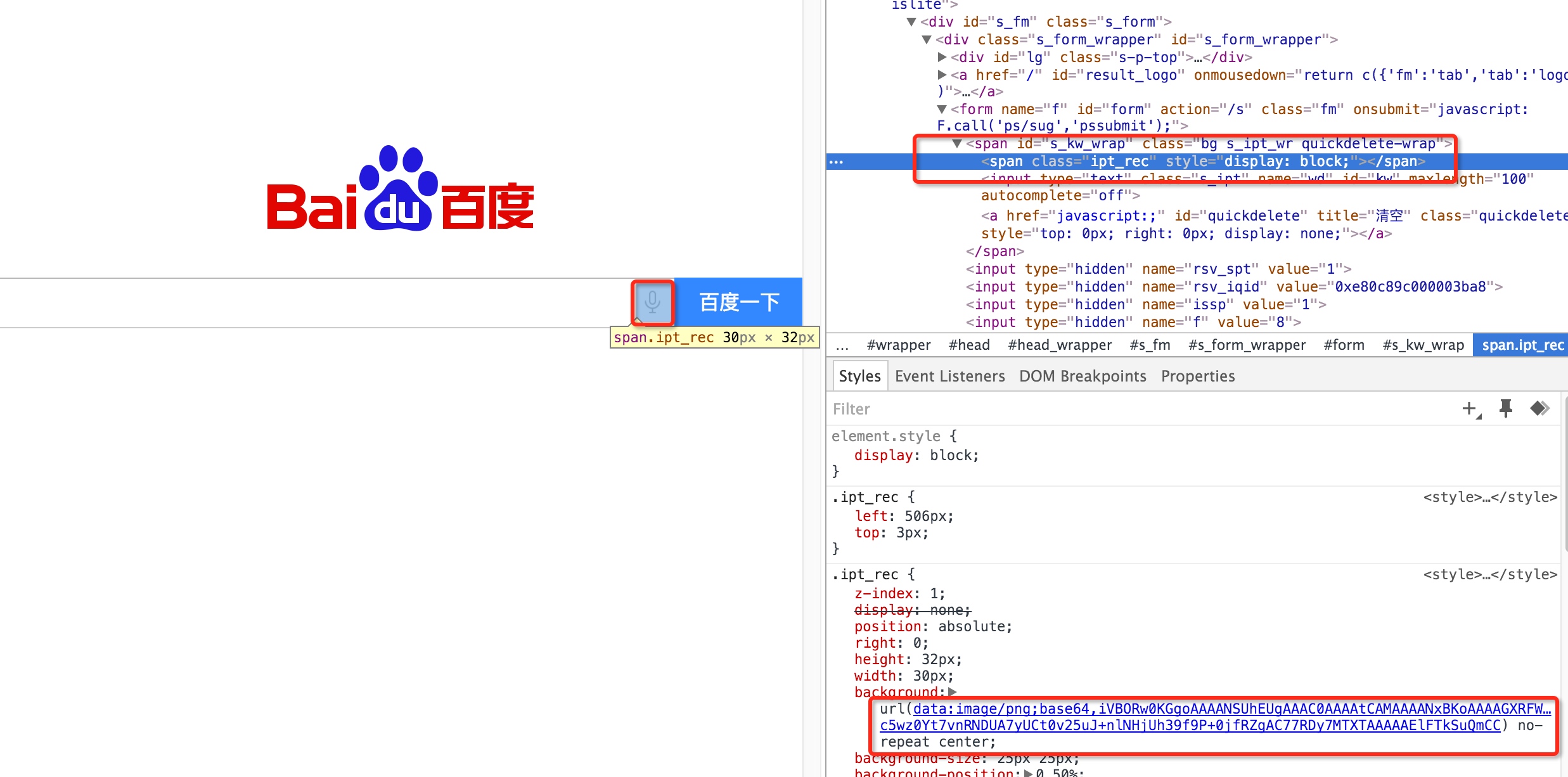
Blob API
Blob 对象表示一个不可变、原始数据的类文件对象。Blob(Binary Large Object)表示二进制类型的大对象。
Blob 由一个可选的字符串 type(通常是 MIME 类型)和 blobParts 组成:
Blob 表示的不一定是 JavaScript 原生格式的数据。比如
File 接口基于 Blob,继承了 blob 的功能并将其扩展使其支持用户系统上的文件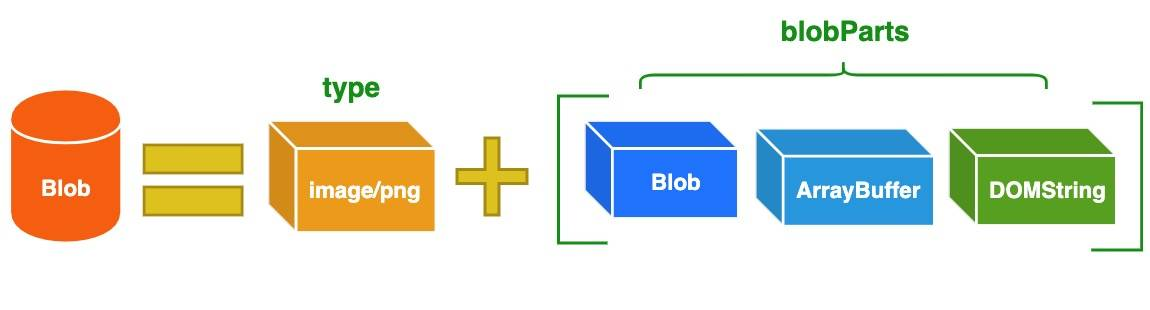
构造函数
var aBlob = new Blob(blobParts, options);blobParts:它是一个由 ArrayBuffer,ArrayBufferView,Blob,DOMString 等对象构成的数组。DOMStrings 会被编码为 UTF-8
options:一个可选的对象,包含以下两个属性:
- type —— 默认值为
"",它代表了将会被放入到 blob 中的数组内容的 MIME 类型。
- endings —— 默认值为
"transparent",用于指定包含行结束符\n的字符串如何被写入。 它是以下两个值中的一个:"native",代表行结束符会被更改为适合宿主操作系统文件系统的换行符,或者"transparent",代表会保持 blob 中保存的结束符不变。
Blob 属性
- size(只读):表示
Blob对象中所包含数据的大小(以字节为单位)。
- type(只读):一个字符串,表明该
Blob对象所包含数据的 MIME 类型
Blob 方法
- slice([start[, end[, contentType]]]):返回一个新的 Blob 对象,包含了源 Blob 对象中指定范围内的数据。
- stream():返回一个能读取 blob 内容的
ReadableStream。
- text():返回一个 Promise 对象且包含 blob 所有内容的 UTF-8 格式的
USVString。
- arrayBuffer():返回一个 Promise 对象且包含 blob 所有内容的二进制格式的
ArrayBuffer。
常用转换
字符串转Blob
//将字符串 转换成 Blob 对象
var blob = new Blob(["Hello World!"], {
type: 'text/plain'
});
console.info(blob);Blob转字符串
//将字符串转换成 Blob对象
var blob = new Blob(['中文字符串'], {
type: 'text/plain'
});
//将Blob 对象转换成字符串
var reader = new FileReader();
reader.readAsText(blob, 'utf-8');
reader.onload = function (e) {
console.info(reader.result);
}Blob转ArrayBuffer
var blob = new Blob(["\x01\x02\x03\x04"]),
fileReader = new FileReader(),
array;
fileReader.onload = function() {
array = this.result;
console.log("Array contains", array.byteLength, "bytes.");
};
fileReader.readAsArrayBuffer(blob);ArrayBuffer转Blob
var buffer = new ArrayBuffer(32);
var blob = new Blob([buffer]);TypedArray转Blob
//将 TypeArray 转换成 Blob 对象
var array = new Uint16Array([97, 32, 72, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100, 33]);
var blob = new Blob([array]);Base64
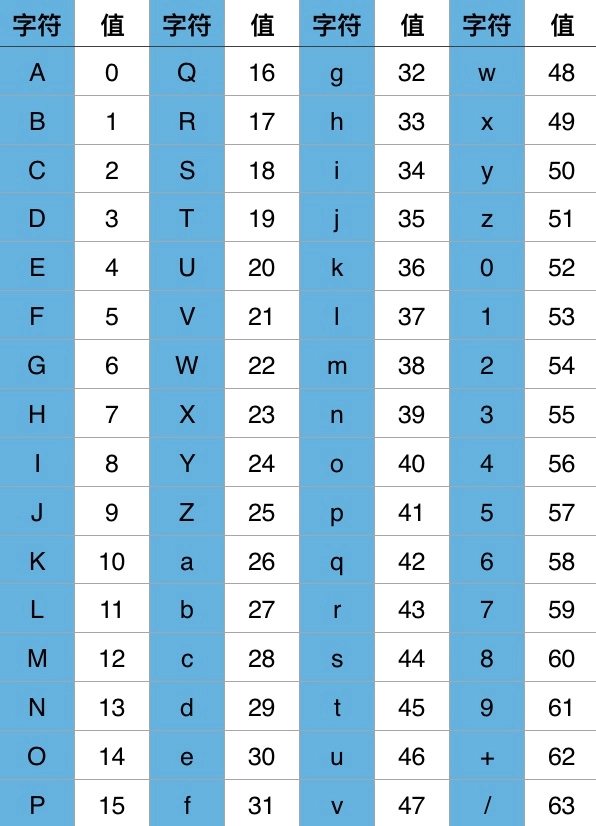
一种基于 64 个可打印字符来表示二进制数据的表示方法
这64个字符对应关系
为什么用Base64
- 计算机最终存储和执行的是01二进制序列,这个二进制序列的含义则由解码程序/解释程序决定。
二进制不兼容。某些二进制值可能被不同硬件解释为不同意义
(在要求使用ascii字符的环境把非ascii的字符ascii化)
base64最早用来邮件传输协议:我们知道一个字节可表示的范围是 0 ~ 255(十六进制:0x00 ~ 0xFF), 其中 ascii 值的范围为 0 ~ 127(十六进制:0x00 ~ 0x7F);而超越 ascii 范围的 128~255(十六进制:0x80 ~ 0xFF)之间的值是不可见字符。当然也并不是所有的 ascii 都是可见的,ascii 中只有 95 个可见字符(范围为 32 ~ 126),其余的 ascii 为不可见字符,因为不同设备对字符处理的不同,这样那些不可见字符就有可能被处理错误
- 很多场景下的数据传输要求数据只能由简单通用的字符组成,比如HTTP协议要求请求的首行和请求头都必须是ASCII编码,还有http的get请求参数传输二进制数据
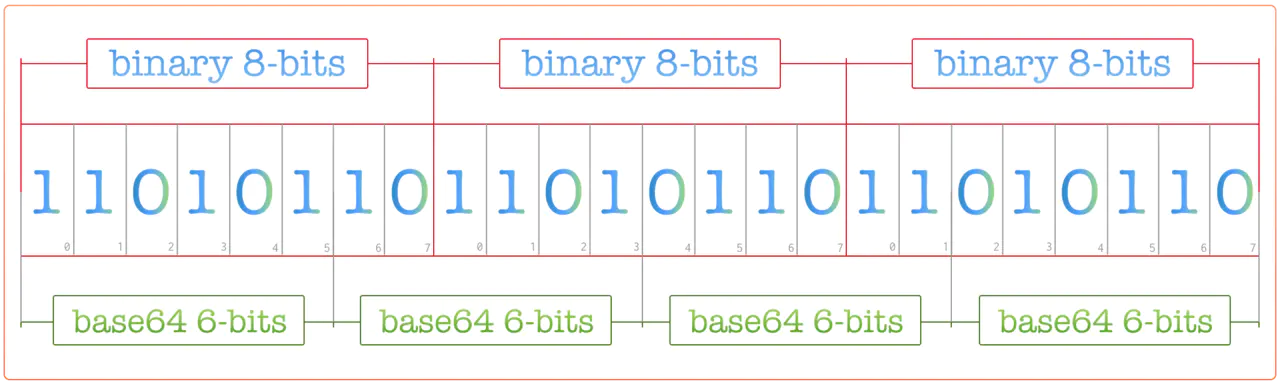
上图是编码示例,原本8字节编码表示为base64变为6字节编码,多出了一个字符,原本3字符的内容,表示为base64需要四个字符。因此base64编码处理之后体积会增加 1/3
浏览器处理API
btoa
- 基于二进制数据 “字符串” 创建一个 base64 编码的 ASCII 字符串
atob
- 解码通过 base64 编码的字符串数据
- 解码中文字符会出现乱码
Node.js
在 Node.js 中, Buffer 对象用于表示二进制数据。
Buffer 类是 JavaScript 语言内置的 Uint8Array 类的子类。只要支持 Buffer 的地方,Node.js API 都可以接受普通的 Uint8Array。
Buffer 的实例(通常是 Uint8Array 的实例),类似于从 0 到 255 之间的整数数组,但对应于固定大小的内存块,并且不能包含任何其他值。 一个 Buffer 的大小在创建时确定,且无法更改。
Buffer全局对象
// 创建一个长度为 10 的 Buffer,
// 其中填充了全部值为 `1` 的字节。
const buf1 = Buffer.alloc(10);
// 创建一个长度为 10、且未初始化的 Buffer。
// 这个方法比调用 Buffer.alloc() 更快,
// 但返回的 Buffer 实例可能包含旧数据,
// 因此需要使用 fill()、write() 或其他能填充 Buffer 的内容的函数进行重写。
const buf3 = Buffer.allocUnsafe(10);
// 创建一个包含字节 [1, 2, 3] 的 Buffer。
const buf4 = Buffer.from([1, 2, 3]);字符编码
// 编码
const buf = Buffer.from('hello world', 'utf8');
// 解码
console.log(buf.toString('hex'));
// 打印: 68656c6c6f20776f726c64
console.log(buf.toString('base64'));
// 打印: aGVsbG8gd29ybGQ=
console.log(Buffer.from('fhqwhgads', 'utf8'));
// 打印: <Buffer 66 68 71 77 68 67 61 64 73>
console.log(Buffer.from('fhqwhgads', 'utf16le'));
// 打印: <Buffer 66 00 68 00 71 00 77 00 68 00 67 00 61 00 64 00 73 00>Buffer 与 TypedArray
Buffer 实例也是 JavaScript 的 Uint8Array 和 TypedArray 实例。 所有的 TypedArray 方法在 Buffer 上也可用。 但是, Buffer 的 API 和 TypedArray 的 API 之间存在细微的不兼容,详细可以查阅Node.js官网